Introduction
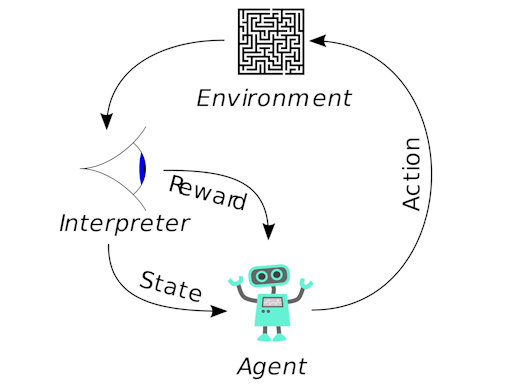
Q-learning is a reinforcement learning technique used in machine learning. The goal of Q-Learning is to learn a policy, which tells an agent which action to take under which circumstances. It does not require a model of the environment and can handle problems with stochastic transitions and rewards, without requiring adaptations.
An application of Q-learning to deep learning, by Google DeepMind, titled "deep Q-learning" that can play Atari 2600 games at expert human levels was presented in 2014.
Q-learning was first invented in Prof. Watkins' Ph.D thesis "Learning from Delayed Rewards", which introduced a model of reinforcement learning (learning from rewards and punishments) as incrementally optimising control of a Markov Decision Process (MDP), and proposed a new algorithm – which was dubbed "Q-learning" – that could in principle learn optimal control directly without modelling the transition probabilities or expected rewards of the MDP. The first rigourous proof of convergence was in Watkins and Dayan (1992). These innovations helped to stimulate much subsequent research in reinforcement learning. The notion that animals, or 'learning agents' inhabit a MDP, or a POMDP, and that learning consists of finding an optimal policy, has been dominant in reinforcement learning research since, and perhaps these basic assumptions have not been sufficiently examined.

Publications