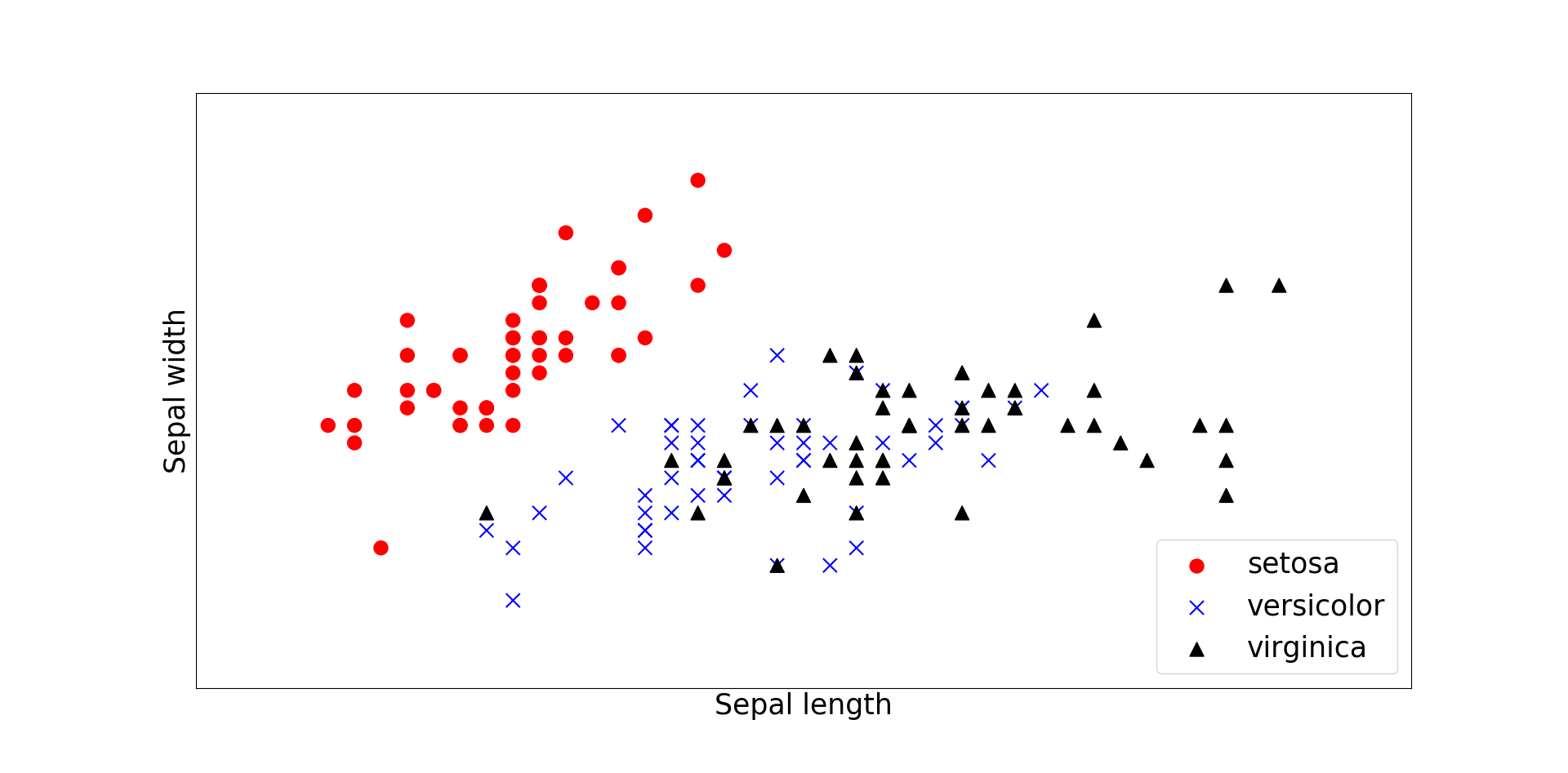
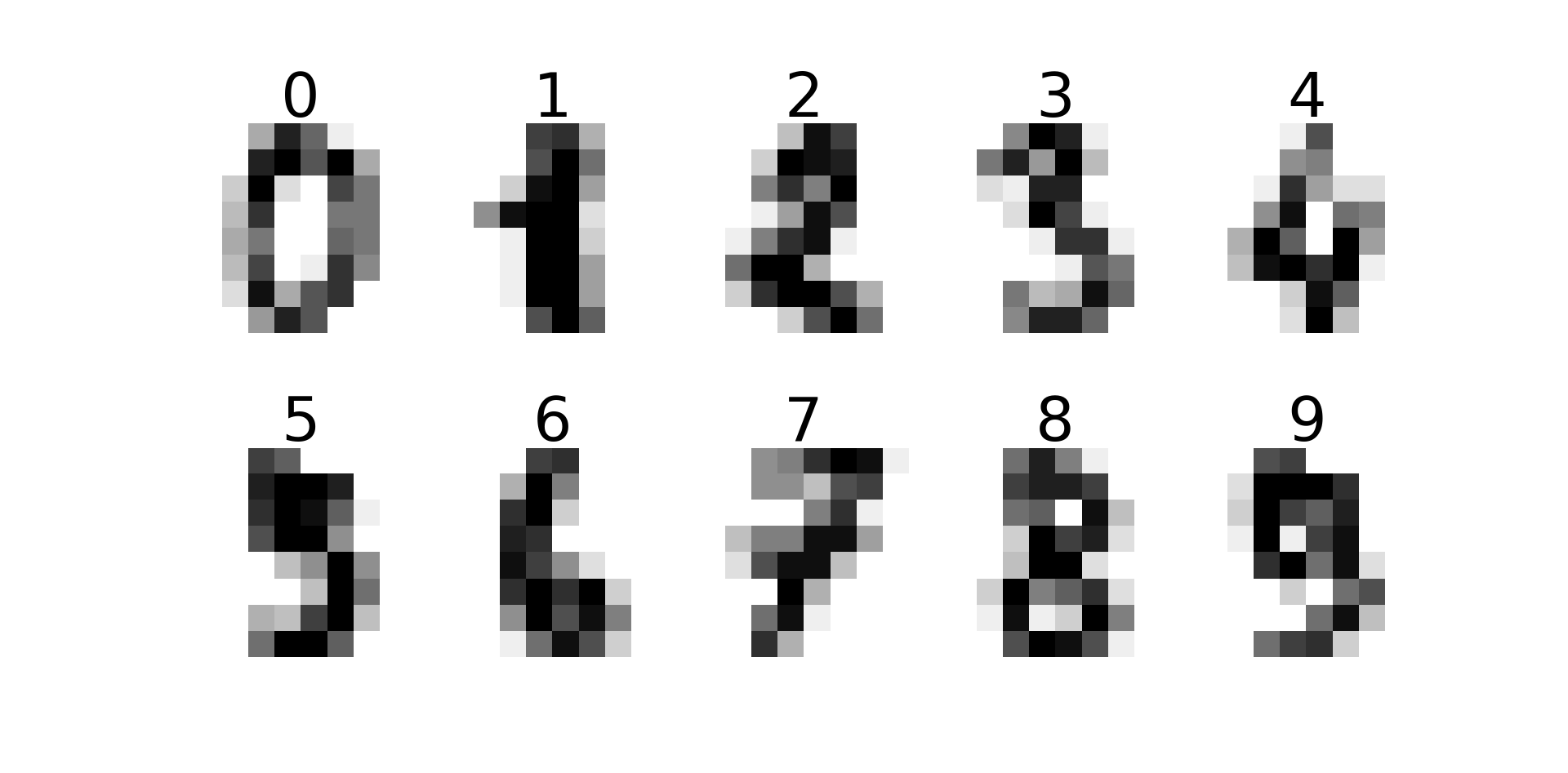Step 1: Pick a data set
We will apply Conformal Prediction on the selected dataset.
We will apply Conformal Prediction on the selected dataset.
This underlying algorithm will be used to calculate how different (or similar) a sample is, to the rest of the dataset.
We call this measure the 'non-conformity' score $\alpha$.
The motivation here is we are trying all potential labels to find the 'best' one that helps the test sample 'fits' well into the dataset.
To measure how 'conformal' the test sample with the given potential label is, we count how many $\alpha_i (1 \leq i \leq N+1)$ that is larger than or equal to $\alpha_{N+1}$ of the test sample, and divide it by the size of the training set.
This result is called the p-value, which is simply the fraction of the training examples as similar as the test sample.
$$p-value = \frac{\#|{i=1,..,N+1 : \alpha_i \geq \alpha_{N+1}}|}{N+1}$$
Intuitively, the higher the p-value of a potential label is, the more confident we are that this label helps the test sample 'fits' into the dataset.
Given any confidence level $1 - \epsilon$ (e.g. $\epsilon = 0.1$ for 90% confidence), the potential labels whose p-value is larger than $\epsilon$ will be accepted.